
It’s Friday afternoon. You are at work. You’ve been working tirelessly for the past hour. It’s time to take a break. You take your phone and place it in front of your face. “Unlocked” — it says. Then, you spend your next 10 mins scrolling on Instagram. But, you start to wonder: “How was the phone able to recognize me and unlock itself?” Let’s find out.
Architecture
Chances are that there is a neural network in your phone that recognizes you. “But, what is a neural network?” — you ask. Well, a neural network is a biologically inspired algorithm that is able to perform classification. “A what?” A classification. Do you remember that episode in Silicon Valley where Jian-Yang developed the infamous “Not hotdog” app? Well, that is a classification: the process in which objects are recognized, differentiated, and understood — Wikipedia. “No, no… a biologically inspired algorithm?” Ah… OK. So, we humans use our brains for a lot of things: thinking and movement, breathing and sleeping, but also for recognition and understanding. Scientists in the 40s developed a mathematical model of the human brain. As computers became more and more advanced it was finally possible to simulate such a model. That’s when artificial neural networks were invented (we already had biological ones, heh). “Hmmm… OK.” — you seem confused. You see, a neural network is a directed graph of nodes. Information flows through this graph. At one end we have the input — an image. At the other, we have the output — a binary variable whose value decides whether to unlock your phone or not. In the middle… that’s where the magic happens. “Magic?” Yes, magic.
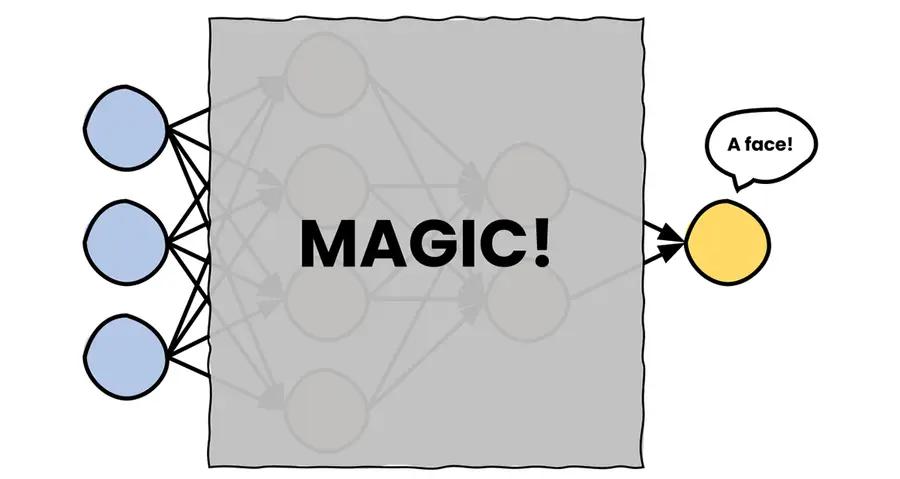
The image gets processed by several layers of neurons in a sequential fashion, where each neuron is connected with all the neurons in the previous layer, and on and on until the very end — a single neuron, that fires up if you appear in the image. BTW, the input image has a special name — the input layer, and the output neuron — the output layer. Every other layer in between the input and the output layer is called a hidden layer.
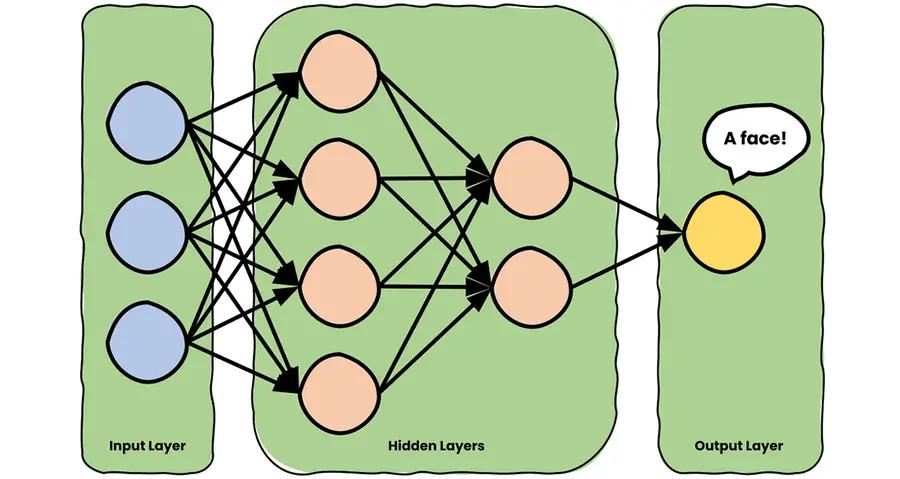
Have you heard about deep learning? “Hm, yes.” — you confirm. Well, deep learning is involved in creating neural networks with a lot of hidden layers. And I mean, a looot. “That’s cool. But what are the neurons you mentioned previously?” Great question!
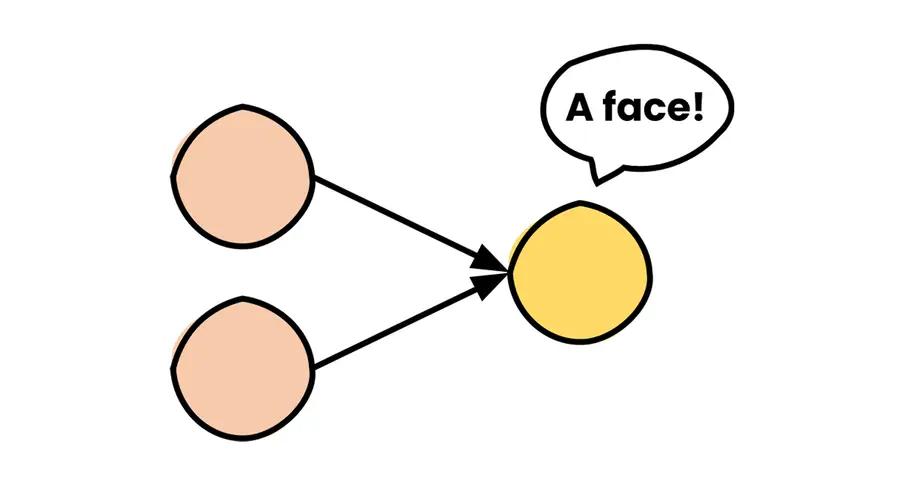
You remember at the beginning, I said: “A biologically inspired algorithm?” Well, our brain has these electrically excitable cells — neurons, responsible for receiving sensory input from the external world, for sending motor commands to our muscles, and for transforming and relaying the electrical signals at every step in between. Artificial neurons mimic this behavior. They receive the output from all the neurons in the previous layer, do some “crazy” math, and output a value themselves. “Math? Not again!” Don’t be scared. They don’t solve a complex integral. What they do is calculate a weighted sum of the values they received. This means that they multiply each value with weight and add the multiplied values together (plus they add an additional value — the bias term at the end, just for fun).
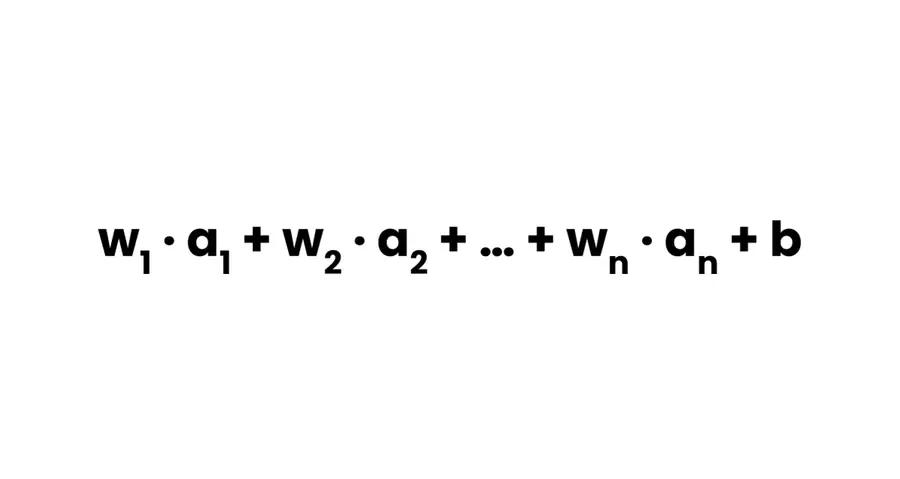
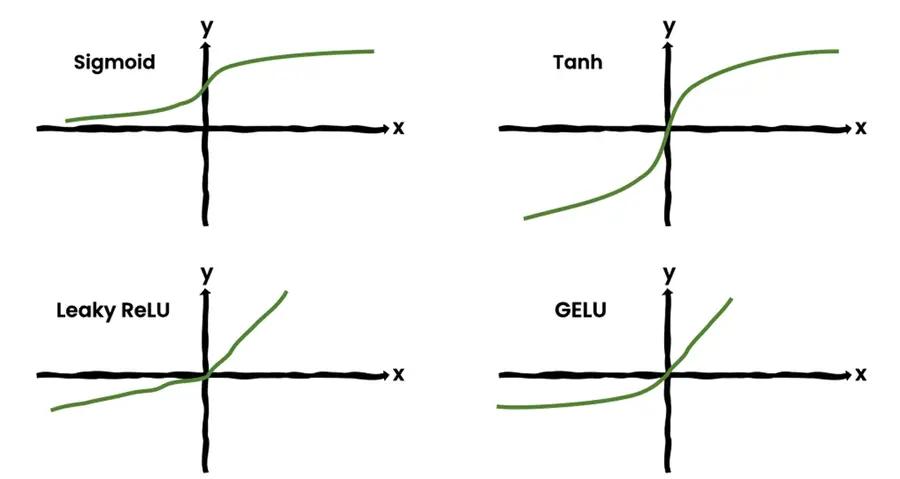
There is a catch though. The value they calculated gets passed through a function, an activation function as we machine learning engineers like to call it. This function gives the neural network more powah! And that is the output of the neuron.
This output, along with the outputs of all the neurons in the current layer, gets propagated to the next layer, and so on until the very last neuron. That’s how the information flows in this structure.
Note, the hidden layers usually use one type of activation function — ReLU, and the output neuron, another — Sigmoid. Why, do you ask? Well, as we said, the purpose of the network is to recognize that the face in the image, if there was one, belongs to you. This recognition comes in the form of certainty. The neural network can be 98% certain or 23% certain. The Sigmoid activation function does exactly that. For any input value, it outputs a value between 0 and 1. You can scale that value to obtain a percentage, but that’s only a technical detail. Now, if the value is larger than 0.5 the output neuron fires, and the phone gets unlocked. The value 0.5 is something we set ourselves. Don’t get me wrong, we can use the Sigmoid activation function anywhere. However, we use ReLU for convenience.
“OK, I get it. You have an image, magic happens, then a neuron fires, and the phone is unlocked. Hooray! But how did the network gain the ability to recognize me? How did it… learn?” Oh, boy. We are in for a ride!
Learning
Let’s see the image of a neural network once more.
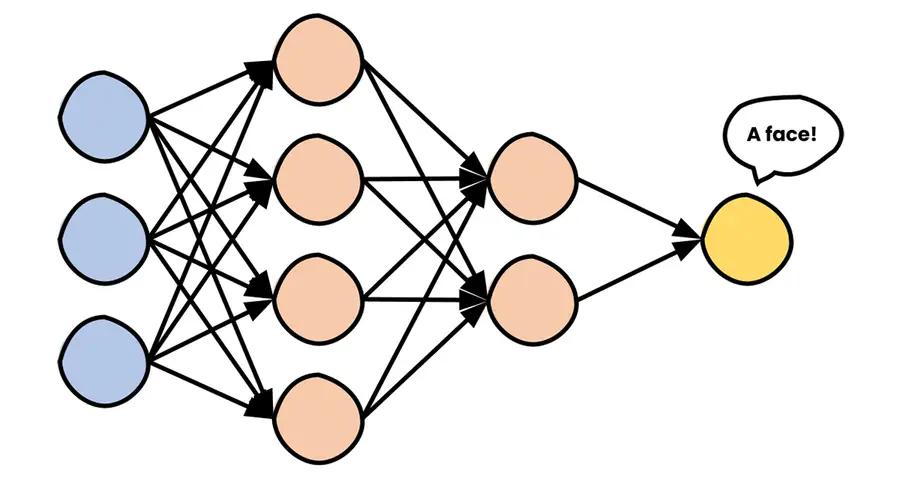
Do you see the lines connecting the neurons between layers? These lines have weights associated with them. As I told you, a neuron multiplies the output of the neurons in the previous layer with weights and adds up the multiplied values (plus adds the bias term, you know… for fun). These weights and biases can have any value. Literally, any value. But, how do we know which values are appropriate such that the network distinguishes between your face and mine, or even if there is a face on the image? We can find them by hand, sure, but doing so for 5 million parameters is not as amusing as it sounds. So mathematicians came up with a solution. They framed this as an optimization problem: for every correctly classified image, the network scores a point, and for every incorrectly classified image, the network doesn’t score a point. A point, no point game. The goal is to optimize the parameters, altogether, so as to get as many points as possible. But for this to work, we need… DATA. Thousands and thousands of images. “Of me?! I barely have 10 selfies on my phone.” — you shout. No, not of you, but of human faces. You see, neural networks are clever. When they learn what represents a face they can easily distinguish between your face and mine.
How does this all work? Imagine that you are a neural network. Weird, right? Bare with me. Imagine that you, a neural network, are standing on a mountain. It’s dark outside and you don’t see much around you. You are desperate and want to go home, and home is downhill. The only thing you have is… DATA — thousands and thousands of images stacked on the palms of your hands. You peek at the first image. A guy. Ginger. Plays guitar and sings about love and stuff. A beam of light from above brightens your surrounding area and you start to see the direction downhill. “This really is weird.” — you think to yourself, as you head home. However, the darkness sets again. Now, you peek at the second image. A girl. Has green hair and looks depressed. The beam illuminates your surroundings once more. Step by step, after seeing all the images, possibly multiple times, you get home, and now you —a neural network, know what represents a human face.
For the tech-savvy, we optimize the loss function (the mountain) — on the x-axis, we have the model’s parameters and on the y-axis, we have a quantity of how well the network performs. For binary classification, we use the binary cross-entropy loss function (the point, no point game). The idea is to find the values on the x-axis, where the quantity is minimal. This function is multidimensional, so it’s impossible to pinpoint the minimum, or even find it algebraically, so instead, we use an iterative method — the stochastic gradient descent (looking at the images one by one and going downhill). This method goes in the opposite direction of the gradient — where the function is the steepest. But, calculating the gradient for a neural network is not a computationally efficient task. It involves differentiation. However, a really smart Canadian scientist found a clever trick to do this really efficiently. Lo and behold the backpropagation algorithm.
Ah, I almost forgot. The bias term! Do you know the good ol’ straight line equation?
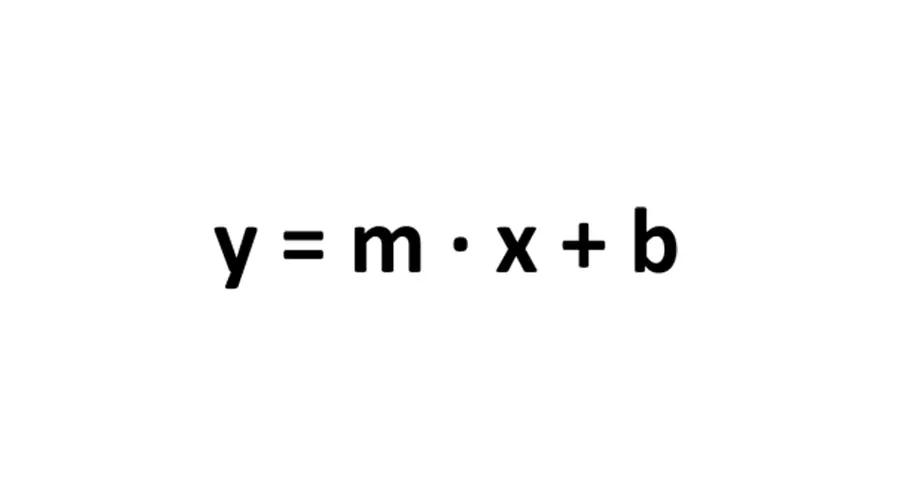
Where m is the slope and b is the intercept with the y-axis? If b didn’t exist we can only represent the lines that pass through the origin. Adding b to the equation and we can represent any line. The bias term is not just for fun. The bias term is used to expand the set of possible models we are able to learn.
Phew! That was a mouthful. But, I would lie if I said that we are at the end. There is much more to neural networks and learning that I was able to cover in this story. Are you interested to hear more? “No, no. I am good for now, thanks.”
About the author
Mladen Korunoski is a data scientist working at our engineering hub in Skopje.Mladen's main interests are Machine Learning and Software Development. In software development, Mladen is versed in multiple programming languages and frameworks. In machine learning, most of his experience is in Natural Language Processing (NLP).
-1.png&w=3840&q=50)
.png&w=3840&q=50)
-1.png&w=3840&q=50)