
In this article, we will demonstrate how to auto-scale your Redis-based applications on Kubernetes.
Why do we need KEDA HPA?
We were in need of HPA, but in our case, we couldn’t scale our Kubernetes application based on CPU or memory usage because almost every request for our application used a lot of resources, so sometimes, we would have unnecessary scaling. We were trying to find a solution to our problem, and what caught our attention was KEDA.
What is KEDA HPA?
KEDA is a Kubernetes-based, event-driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needed to be processed. KEDA is a single-purpose and lightweight component that can be added to any Kubernetes cluster.
KEDA works alongside standard Kubernetes components like the Horizontal Pod Autoscaler and can extend functionality without overwriting or duplication. With KEDA you can explicitly map the apps you want to use event-driven scale without stopping other apps from functioning. This makes KEDA a flexible and safe option to run alongside any number of other Kubernetes applications or frameworks.
As we already mentioned, KEDA can be triggered on other events like rabbitmq, kafka, etc.We could look at KEDA as an intelligent HPA which is able to scale up and scale down pods based on custom metrics.
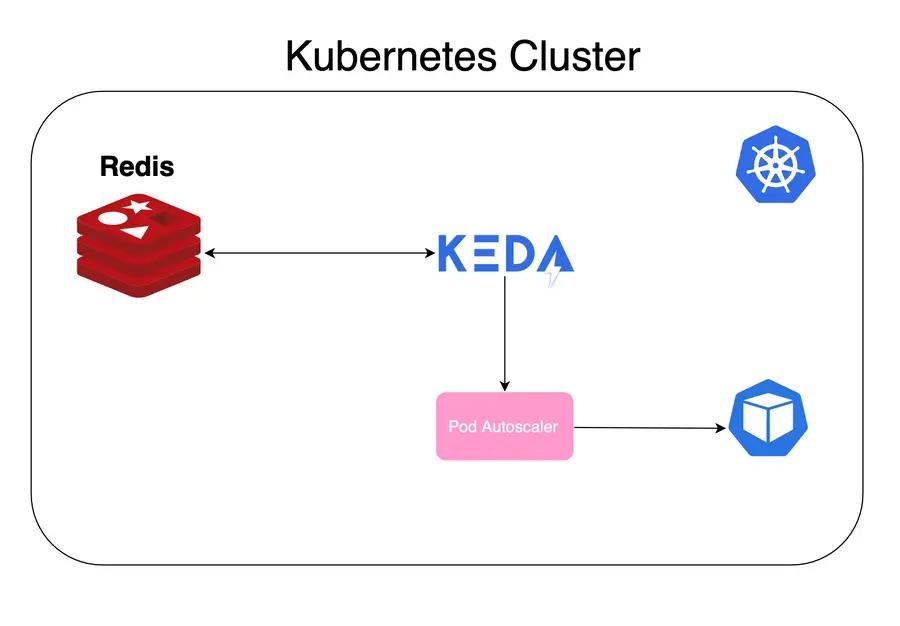
KEDA Redis architecture in Kubernetes cluster:
How to Deploy KEDA in a Kubernetes cluster?
We can deploy KEDA in multiple ways:
- Deploying using the deployment YAML files
- Helm chart
Whichever method you use, the effect is the same. We need to deploy two things, the first thing is a group of resources for KEDA to operate (KEDA namespace, KEDA operator, KEDA API, etc.) and a scaled object, thus instructing KEDA on how to scale pods and based on what.
Yaml example of Scaled object for KEDA:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: redis-scaledobject-dev
namespace: dev
spec:
scaleTargetRef:
kind: Deployment
name: worker-celery-dev
pollingInterval: 15
cooldownPeriod: 200
maxReplicaCount: 10
minReplicaCount: 2
triggers:
- type: redis
metadata:
address: redis-master.dev.svc.cluster.local:6379
username: redis_user
enableTLS: "false"
listName: celery
listLength: "10"
spec.scaleTargetRef - with this option, we are telling KEDA what needs to be scaled
spec.pollingInterval - with this option, we are telling KEDA how much material the second Keda should check and whether changes need to be made
spec.cooldownPeriod - this is the option with which we are telling KEDA how long it will hold running pods after it notices that they are not necessary for scaling
spec.maxReplicaCount - this is the number that tells KEDA the maximum number of replicas it could run
spec.minReplicaCount - this is the number that tells KEDA the minimum number of replicas it could run
spec.triggers - in this section, we are instructing KEDA on the event on which it should be triggered. Some parameters are IP address or host name with port of Redis, username and password (optional) with which KEDA logs in on Redis and checks the number of requests in Redis list. After this, we can enable or disable TLS between KEDA and Redis, specify a name of Redis list and the number of the longest Redis list on which KEDA will trigger scaling.
Why should we use KEDA?
- It upgrades existing Kubernetes primitives (such as Horizontal Pod Autoscaler) to scale any Kubernetes container based on the number of events to be processed
- It’s easy to implement
- Works reliably
- It takes up very few resources
- Upgrading KEDA API is very quick and easy
Kubernetes commands for KEDA debugging:
- kubectl get hpa -n namespace (namespace where the scaled object is) - if the scaled object is connected to Redis, we will see some value in TARGETS (in our case it is 0/10)

- kubectl describe hpa keda-scaled-object-name -n namespace - With this command, we can check if there are some errors and information related to scaling

- kubectl get pods -n keda - We can now check the status of the API metrics and operator pods and describe their errors if any

- kubectl logs keda-metrics-apiserver -n keda - List logs about KEDA metrics and KEDA operator
Conclusion
My experience has shown that using KEDA is a very easy way to scale pods on the Redis metric. I’m looking forward to using it in the future and integrating its autoscaling functionality with our internal services. All in all, I would highly recommend using KEDA for scaling pods on custom (Redis list) metric.
-1.png&w=3840&q=50)
-1.png&w=3840&q=50)
